|
OpenTracing? OpenTracing!
-
dev
-
2020 February 26
|
OpenTracing? 넌 누구니. 왜 필요하니.
이 글은 팀에 OpenTracing을 소개하기 위해 작성했던 글로 일부 내용 수정해서 블로그로 옮겨왔습니다.
이제는 대부분 서비스들에게 분산 인프라 환경이 보편화되면서 복잡도를 가지게된 인프라 환경의 모니터링과 운영 이슈 처리에 관심을 많이 가진다. 그래서 분산 환경에서의 디버깅용 로깅을 어떻게 하면 좋을까 찾다가 알게된 OpenTracing에 대해 정리해보았다.
OpenTracing이란
이 공유에서 언급될 OpenTracing은 CNCF 산하의 프로젝트로 단어 그자체 처럼 하나의 흐름을 공개적으로 추적하기 위한 기능을 표준화하는 프로젝트입니다. 아직 공식적인 OpenTracing의 표준은 존재하지 않고 CNCF가 가장 큰 기구이기 떄문에 Cloud환경의 입김(question)이 쎄서 주목받는 비공인 표준 입니다. 현재 해당 OpenTracing spec을 기준으로 만들어지는 Tracer들로는 Zipkin, Jaeger, Lightstep등 다양하게 존재합니다. (CNCF사이트 supported tracer목록에 zipkin이 빠져있는건 왜 그런지 궁금하네요)
이제는 서비스를 운영하는 대부분의 서버 개발자들에게 MSA가 보편화되고 여러 효율성 관점에서 도입되고 있을 때, 이런 분산 환경의 로깅이 주목을 받으며 OpenTracing이 그 방안으로 나오고 있습니다. 사실 OpenTracing은 분산 환경의 로깅을 목적으로 만들어진 것이 아니고 하나의 request에서 response를 반환 할 때까지 거치는 서버의 연결 점들을 추적하기 위한 시스템으로 시작된 것이었습니다. 이 서버 연결을 추적하다보니 자연스럽게 해당 서버들의 req/res latency를 확인할 수 있게되어 bottleneck check가 가능하게 되고 그 서버 안의 로그까지 합쳐져 코드레벨의 디버깅도 할 수 있는 기능들도 들어가게되었습니다.
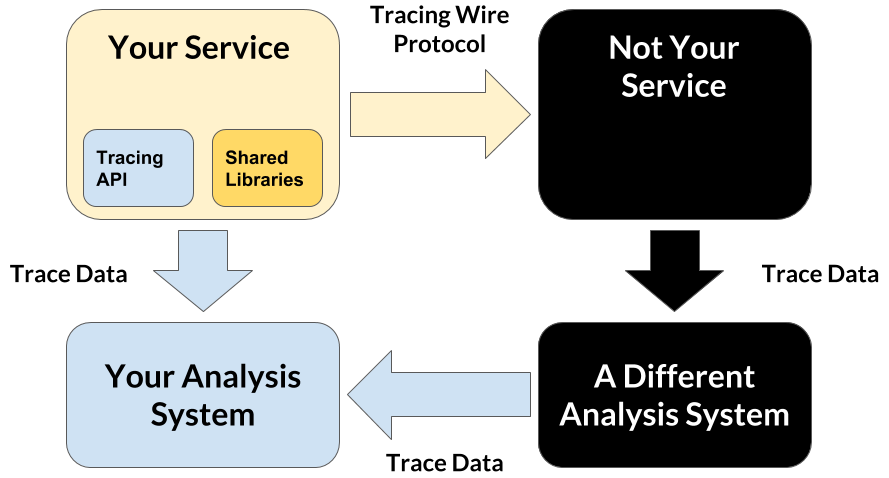
표준화를 시도하는 이유는 OpenTracing Big Piceces(위 그림)에도 설명되어있지만 OpenTracing이 표준화된다면 우리 서비스의 분산 로깅만 가능한 것이 아니라 우리 서비스에서 외부서비스로 연결시 최초 요청의 trace id로 연결되어 모든 연결 구조의 추적이 가능하게 됩니다. 예를 들어 빌링 서비스도 우리가와 모두 같은 tracer 기준으로 opentracing 을 설정한다면 장애발생시 좀 더 빠르게 확인이 가능하곘죠? :-)
왜 OpenTracing을 갑자기?
현재 (회사)팀의 환경에서 운영중인 서버가 단일 서버군을 참조하는 것이 아니고 요청에 따라 복수개의 서버군을 거치게 됩니다. 이럴 때 서버간 로그가 통합관리되는 것이 아니라 문제에 대한 디버깅시 로그를 각자 찾거나 bottleneck을 찾기하는 활동을 할때 각 서버의 로그들을 따로 뒤져봐야하는 불편함이 있습니다. 거기에다 각 서버별 로그를 연결된 reqeust/response를 찾아서 보는 것이 정말 쉽지 않은 일입니다. 앞으로 팀에서 관리하는 서버군의 복잡도가 올라가고 분산 환경이 더 커지게 될 수록 디버깅 작업의 난이도가 올라가고 개발자의 피로도가 올라갈 것이 예상되기 때문에 이러한 작업이 진행되면 차후 편안한 디버깅 생활을 할 수 있을 것 같아 도입검토가 필요합니다. 물론 디버깅할 일이 없게 코딩을 잘하면 좋겠지만 현실은….ㅋ. 최근 팀에서 검토중인 istio가 팀에 녹아들거나 한다면 더욱 편하게 OpenTracing환경을 도입할 수 있게됩니다.
OpenTracing spec에 대해서 간단하게 오버뷰를 해봅니다. 우선 OpenTracing에서 사용하는 Data Model들을 먼저 이해하면 관련 문서를 참조시 도움이 될거라 간단하게 짚어봅니다.
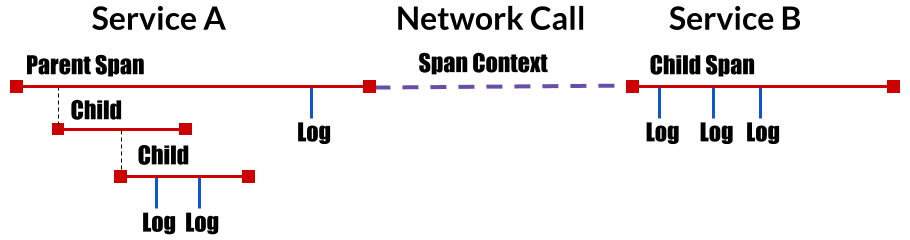
- Span
- OpenTracing Data Model의 기초 단위로 시작과 끝을 가지는 Timeline block입니다. 다시 말해 시간을 측정하게되는 모든 단위를 뜻 합니다. 시간을 측정한다는 것은 측정 시작 지점과 종료 지점이 있으니 그것이 하나의 Span이 됩니다. Span은 Parent / Child 구조를 가지고 있는데 이것은 우리가 흔히알고있는 Tree Node의 Parent Child와는 조금 다르게 하나의 Span을 세부로 나누었을 때의 전체가 Parent, 하부에 포함되어있는 Span이 Child Span이 됩니다. 예를 들어 하나의 api reqeust/response가 하나의 Span이라면 그 reqeust를 처리하는 내부 코드 method call 하나하나를 Span으로 생성시 method Span은 Child Span이 됩니다.
- Span은 하위의 attribute들을 들고 다닙니다.
- Operation Name
- start / finish timestamp
- Tags
- key/value 구조의 사용자정의 필터 값들
- Logs
- SpanContext
- 각 Tracing 구현체에 따라 달라지는 내용. 기본적으로 trace id와 span id등이 포함됩니다.
- Tracer
- 위 Span들에게 특정 id를 부여하여 발송하고 저장하는 시스템을 말합니다. Zipkin, Jaeger 와 같은 것들을 지칭합니다.
동작 원리
동작 원리는 의외로 간단합니다. 위에서 설명한 Span단위의 정보들을 특정 Storage서버에 전달하면 해당 시스템은 그 Span들을 Trace ID, Span ID별로 Timestamp 정렬하게 됩니다. Tracer 별로 SpanContext 구조나 형태가 다를 수 있어 Tracer별로 서로 Span을 공유하지는 못하고 컨버터들이 존재는 합니다
Zipkin Example Flow - https://zipkin.io/pages/architecture.html
OepnTracing을 통해 우리팀이 얻을 수 있는 것
- 위에서도 언급하였지만 결국 빠른 이슈 원인 파악이 최고의 장점입니다. OpenTracing은 단순히 reqeust/response network 연결에 대한 것만 추적이 가능한 것이 아니라 Redis / MySql 과 같은 외부 캐싱서비스나 데이터베이스의 연결 까지도 추적할 수 있어 문제가 발생한 호툴이 어디까지 진입하였고 어디에서 문제가 발생하였는지 빠르게 확인 가능하게 됩니다. 장애 발생시 로그 수집 서버에 Trace ID만 찍어주면 불편하게 키바나에서 이리저리 쿼리 날리면서 로그 찾기 안해도 됩니다.
- 팀에서 OpenTracing의 성숙도를 올리고 다른 팀에 전파가 가능하다면 타팀과의 api 협업시 이슈 해결에 더더욱 효과적이 될 것입니다. 이슈에 대한 해결 능력이 좋아지면 서로서로 윈윈이겠죠?
OpenTracing을 통해 해야할 일
이렇게 좋은 것을 왜 이제야! 그리고 왜 다른 곳은 안하지? 에 대해 고민해보면 답은 사실 간단합니다. 인프라 구조가 복잡도 + 디버깅의 어려움 vs 환경 구성에 대한 불편함 의 내적 대결 구조가 있기 때문입니다. OpenTracing 환경 구성을 위해서는 처음 설정에 노오오오력이 들어갑니다. 세상에 쉬운일은 없습니다. 하지만 조금 노오오오오력 해서 구성하면 후세에 편안함이 올거라 생각됩니다. 그래서 할일을 나열해보면…
- OpenTracing 기술 스택 선정 - Tracer 선정
- Tracer Server 설치
- 각 서버군별 적합한 Tracer Library 설치 / 설정
- Spring인 경우 Sleuth + Sl4j로 떙이지만… play+jdk7, ruby..는..;;; 좀 더 찾아봐야함.
끗
|
|
----------------------------------------
"OpenTracing? OpenTracing!" 끝
----------------------------------------
|
|
CoroutineScope, CoroutineContext, Job
-
dev
-
2020 February 25
|
CoroutineScope, CoroutineContext, Job 공부해보자
사내 프로젝트를 진행하면서 cache 갱신 부분을 coroutine을 통한 비동기 동시 처리를 하고 싶었는데 coroutine의 동작이 생각했던 방향과 차이가 좀 있어서 이유를 확인하려고보니 CoroutineContext와 Scope에 대한 이해가 좀 부족한 것 같아 이부분에 대한 이해가 좀 더 명쾌해지도록 공부하고 기록합니다.
학습 목표
- CoroutineContext, CoroutineScope, Job 간의 관계에 대한 이해
- Coroutine의 내부 동작에 대한 이해
- 서버사이드 Coroutine 사용시 주의해야 할 것들에 대한 정리
- 실제 kotlinx.coroutines github repo의 코드 Tour
학습 자료
- 뭐든 만든사람의 이야기와 동작 구조 이해하는게 우선
- “비슷한 형태의 것들에게 사용 의도가 다르다면 그 다름을 강조하기위해 명명을 달리준다.”
- CoroutineContext
- 모든 Coroutine은 context를 가지게되고 해당 context는 CoroutineContext의 구현체다.
- context는 엘리먼트들의 세트고 coroutineContext property를 통해 현재 coroutine context에 접근 가능하다.
- coroutine context는 immutable이다.
- 하지만 plus op를 통해서 엘리먼트들을 추가가 가능하고 이로인해 새로운 context 객체가 생성된다.
- Job
- 우리가 말하는 coroutine은 Job으로 표현된다.
- coroutine의 생명 주기, 취소, 부모자식관계 등을 책임진다.
- 현재 Job은 현재 coroutine context에서 접근가능하다.
- CoroutineScope
- coroutineContext property 하나만 가지고 있다.
- context를 제외하고는 아무것도 가진것이 없다. - 여기서 문제. 왜 CoroutineContext와 CoroutineScope 명칭을 달리 존재하는 걸까!?
- context와 scope는
의도하는 목적(intented purpose)이 다르다
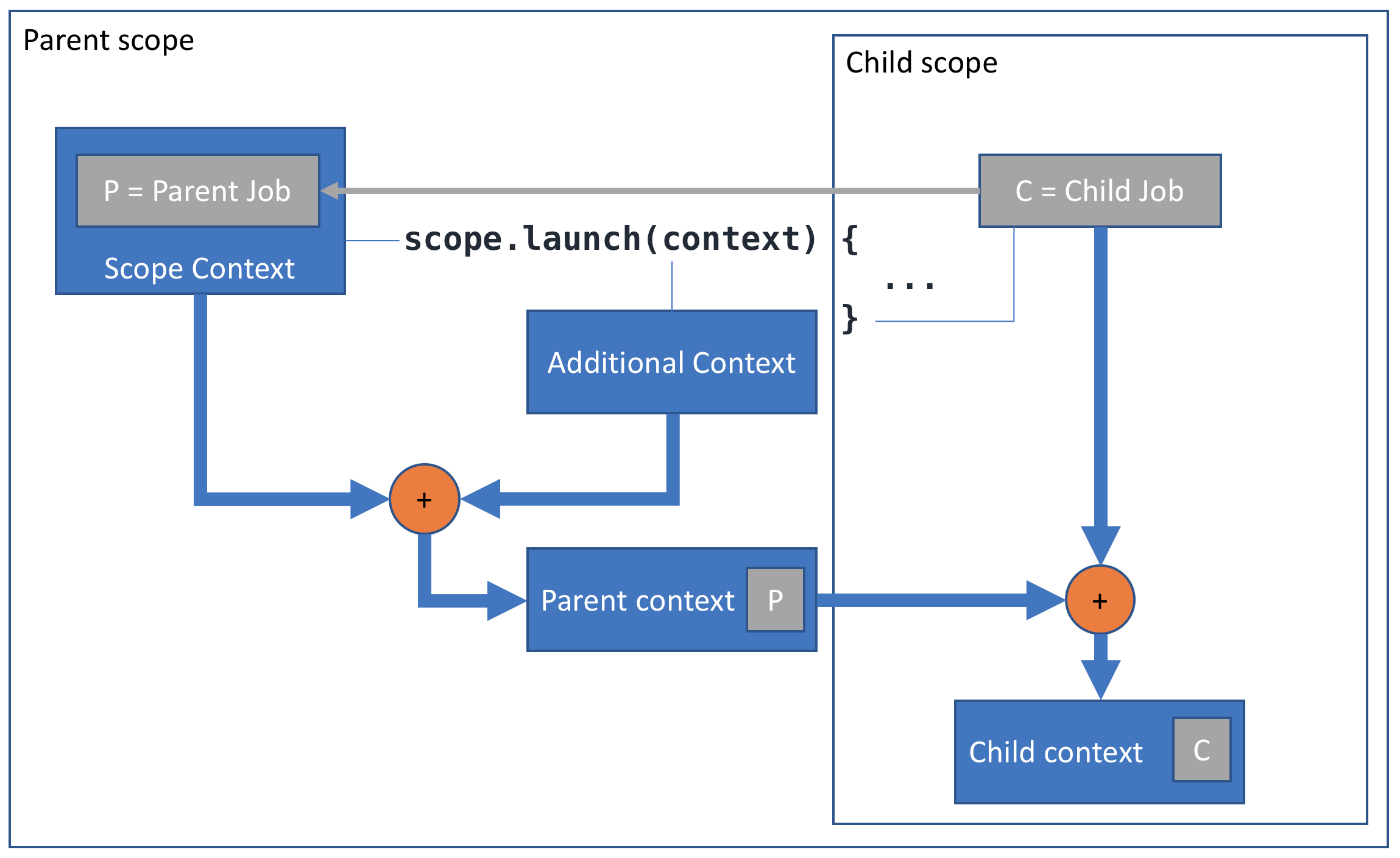
- coroutine은 launch함수를 통해 생성이 되는데 launch함수는 context를 가진 CoroutineScope의 extension 함수로 제공된다. 그리고 launch는 CoroutineContext를 parameter로 넘겨 받는다 결국 launch함수를 통해 두개의 CoroutineContext를 핸들링하게 되는데 그 이유는 새로 생성되는 Job(=coroutine)에 child context를 전달해주기 위함이다.
- 내가 그래서 context와 scope의 이해하기로는 scope은 본인이 가지고 있는 하나의 context가 영향을 주는 범위를 한정하기 위해 정의된 것으로 보인다. launch함수 호출시 새로운 context 첨부하지 않으면 EmptyCoroutineContext가 기본으로 설정되는데 그말은 새로운 CoroutineContext추가 없이 현재 launch함수의 scope에서 해당 coroutine을 수행하겠다는 뜻이된다.
- context가 plus되어 부모/자식 관계가 생기는 시점에 context가 합쳐지는 것은 context가 가진 엘리먼트들이 합쳐진다는 것이다. 이때 scope context의 엘리먼트보다 parameter context의 엘리먼트가 우선시된다.고 써있다.(It merges them using plus operator, producing a set-union of their elements, so that the elements in context parameter are taking precedence over the elements from the scope.)
- 그리고 scope context에 포함된 엘리먼트들은 parent로서 새로 생성되는 child context에 상속되어 사용할 수 있게된다.
- 결국 scope는 context영역의 한정과 새로운 context에게 상위 엘리먼트의 상속을 가능하게 하기위한 의도(intended purpose)로 만들어진 것이다.
- 이것을 보고 이해가 되기 시작했는데 궁금점이 생긴다. 그럼 CoroutineContext가 가지고 있는
엘리먼트들?은 과연 어떤 것들일까?(나중에 코드 까보면서 확인해보자)
- 함수 반환 이후에도 백그라운드에서 동작하는 coroutine을 수행하고 싶다면 CoroutineScope에 확장함수를 만들어서 수행하거나 CoroutineScope을 넘겨 받아 수행하도록 하면 된다. 해당 함수는 suspend로 만들어선 안된다.
fun CoroutineScope.doThis() {
launch { println("I'm fine") }
}
fun doThatIn(scope: CoroutineScope) {
scope.launch { println("I'm fine, too") }
}
- GlobalScope가 백그라운드 작업 수행을 위해 서버사이드에서는 간편한 기능으로 쓰고 싶은데, 담당 개발자가 떡하니 이런 글을 써놓았으니 읽어봐야겠다.
- GlobalScope의 Dispatcher와 launch 기본 Dispatcher는 Dispatchers.Default로 동일 해서 마치 두개의 launch 함수 동작은 동일 할 것 같지만 실제로 runBlocking 하위에서 동작해보면 둘의 동작이 다르다.
- 결국 Scope의 lifetime 관리를 쉽게할 수 있느냐의 여부. GlobalScope를 사용하면 이전 scope 연계를 무시하고 바로 global coroutine에서 동작하기 때문에 해당 coroutine으로 생성된 job으로 lifetime 관리를 해주지 않으면 원하는 동작결과를 얻을 수 없다.
- 하지만!! 굳이 job control이 필요 없다면 쓸 수 있지 않을까?
- App 개발자인 경우 Coroutine에서 UI resource release등의 작업을 처리하는 일이 있어 해당 작업이 leakage를 일으킬 가능성 때문에 중요하지만 서버사이드 작업에 resource release같은 작업이 없다면 문제 없을(question) 것 같다.
- 테스트를 좀 해보자.
코드 Tour
- CoroutineScope.launch - (Builders.common.kt)
- 로만 블로그에서 설명하는 Scope, Context 구분 통합의 중요한 함수 코드
- CoroutineScope.newCoroutineContext - (jvm/src/CoroutineContext.kt)
- 실제로 context를 합치는 동작을 하는 곳
- multi platform 지원을 위해 js/jvm/native 로 분리 구현되어있다. 일단 jvm만 먼저 보자.
- CoroutineContext.plus operator - (stdlib/CoroutineContext.kt)
- 실제 Context 통합 코드. Element interface도 가지고 있음.
- CoroutineContext iterface 파일은 stdlib에 들어있고 op를 제외한 CoroutineContext의 실제 구현 함수들은 모두 kotlinx.coroutine에 들어있다. 라이브러리 의존성 이슈 때문에 이렇게 해놓은 것 같다. 신기한 패턴이다. 참고
- 그래서 CoroutineContext.kt 가 kotlinx에도 있는데 이건 actual 구현만 있음.
- interface Element
- context가 들고 있는 것들.
- Element도 CoroutineContext interface를 상속했음.
- 코드를 찾아보니 아래의 것들이 Element를 상속해서 만들어짐
- ThreadContextElement
- AbstractCoroutineContextElement
사용시 주의 사항
결론
원래 하고자 했던 작업은 stale cache의 refresh를 서버 request/response latency loss 없이 백그라운드에서 처리하는 거였다. GlobalScope는 kotlin에서 predefined된 Scope여서 나 말고도 여기저기서 쓸 수 있다는 가능성이 있어보여 결국 Cache 서비스만의 Scope를 object로 생성해서 사용하는 방법을 채택해 테스트 해보려고 한다. 하지만 위에서 살펴본 것처럼 해당 Scope로 만들어지는 coroutine들에 대해서 job 처리를 따로 해줘야하는데 refresh에 대한 것이 fail over 로직도 따로 있고 loss가 있는 부분이 없어보여 job처리는 skip한다. 아직 필요성을 못찾음.
|
|
----------------------------------------
"CoroutineScope, CoroutineContext, Job" 끝
----------------------------------------
|
|
Review the KotlinConf 2019 Cophenhagen
-
dev
-
2019 December 08
|
KotlinConf 2019 Copenhagen 되돌아보기
작년 겨울 지인을 통해서 알게된 KotlinConf. 호기심으로 신청해서 참석한 이번 행사의 후기를 남겨보자. Kotlin에 대한 애정(?)을 더욱 키워주고 흥미로운 내용들이 많았다. 참관기를 크게 내가 배운 내용들과 행사에서 느낀 분위기들. 그리고 꼭 다른 분들에게 전달해주고 싶었던 나의 생각들 정도로 나누어서 줄줄이 써보자. 세션의 주제별로 정리는 따로 글을 남기겠다.
분위기
기존에 다녀왔던 해외 컨퍼런스가 구글 I/O와 JavaOne 두 가지 뿐이기 때문에 비교하기에 무리가 있지만, 유럽에서 열리는 해외컨퍼런스라 그런지 유럼(?)이라는 독특한 분위기가 있었다. 미국의 행사보다는 좀 차분하다는 느낌? 어쩌면 대부분의 참석자가 백인들로 인종 다양성이 떨어지다보니 다양함이 좀 부족해서 그런 것이거나, 날씨가 춥고 비가오는 날씨여서 그런지 행사가 막 흥이나고 신나는 분위기 보다는 차분하게 세션을 열심히 들어야하는 다큐적인 컨퍼런스였다. 외부 참여 부스 수는 좀 적었지만, Jetbrains, Google, Gradle 3 부스만으로 일당백 ㅋ. 참석자 성비는 남성이 압도적이었다. 사실 구글 I/O에서는 매년 참석할 수 록 성비가 평준화 되는 느낌이었는데, Kotlin관련 기술에 집중된 컨퍼런스라 그런지 남성이 대부분. 해외도 아직 기술직군이 남성편향인 것이 체감 되었다. 그리고 여기도 역시 개발자들이라, 아니면 유럽이라 그런지 세션 끝나고 질문하는 사람이 많이 없다. 모국어가 아니라서 그런지 역시 ㅎㅎ. 아 그리고 인종 다양성중에서 아시아쪽 참여는 느낌이 1%도 안되는 것 같았다. 한국인 개발자는 같이간 7명이 전부인 듯 했고, 일본인 개발자, 베트남 개발자 분들 좀 보이고 중국인 개발자도 안보였었다. 아직 행사의 Name value가 거리의 문제와 언어의 장벽을 넘을 정도로 높지 않아서일 것 같다. 그래서 뭔가 개척하는 느낌은 나쁘지 않았다.
KotlinConf Hot Keywords
Why Kotlin?
이번 행사에서 내가 들었던 세션 슬라이드 초입에 언제나 Why Kotlin? 이란 내용이 들어있었다. 아직 Kotlin이 더 확대되기 위해? 개발자들에게 어필하기위해? 발표자들이 이번 행사에서 본인의 이야기를 첨언하여 참석자들에게 약을 파는 내용으로도 느껴졌다. 대부분 Kotlin을 사용하는 이유로 Kotlin 언어의 Null safety, Concise를 들었고 흥미로웠던 이유는 Sexy, Pleasure. 이중에서 내가 가장 공감이 되었던 것은 단연 Pleasure였다. 뭐든 재미가 있어야 한줄이라도 더 짜게되고, 이해도 더 잘되는 것 같다. 나에게 있어 호기심 지속의 기반은 역시 흥미와 재미이다.
Jetbrains에서 생각하는 Kotlin의 비전으로 Multiplatform을 이번 행사 내내 강조했다. Jetbrains 부스에서 진행된 Kotlin Locator라는 행사용 게임앱 역시 Kotlin Native의 샘플앱으로 iOS, Watch용을 제공했다. 여담이지만 11등을 해서 10등까지주는 RasberryPi4를 못받았다 ㅠㅠ. Kotlin이 모든 분야의 Default Language가 된다면 한 분야에서 Kotlin에 익숙해진 개발자는 다른 분야의 접근시 언어 습득의 장벽을 최소화하고 코드 리딩의 어려움을 줄여줄 수 있다. 거기에 한프로젝트안에 포함된 여러 platform에서 모든 코드부분을 공유할 수는 없겠지만, 비즈로직을 포함한 라이브러리를 공유하는 방식도 가능해진다. Jetbrains가 원하는 Kotlin의 미래는 요런 상황인 것 같다. 그래서 Jetbrains는 이 비전 달성의 로드맵에 중요한 요소로 개발자 생태계를 꼽았다. 많은 사용이 있는 것이 좋은 것이고, 좋은 것은 많이 사용할 것이라는 선순환을 만들기 위해 모든 채널로 Kotlin의 홍보와 외부 Feedback을 받을 것이라한다. Jetbrains의 Kotlin팀이 Devrel 팀과 월드투어를 한다는데 이것이 그 액션의 일환일거다. Multiplatform을 지원하는 언어의 시도는 많이 있어왔지만 실패한 역사들을 많이 봐왔다. 하지만 Android를 넘어 이제 Server side에 깊숙히 침투 했으며, Web front로 확장중이다. 그러면서 iOS도 발걸음을 때었다. 하나의 비전안에서 차곡차곡 미션을 해쳐나가는 Kotlin의 앞길이 기대되고 Kotlin이 좋은 개발자로서 잘되기를 기원하는 중이다.
Coroutines - Flow
이제는 Kotlin == Coroutines인 느낌이다. lightweight한 비동기 동시성 기능을 엄청 강조한다. 컨퍼런스의 세션중에 코루틴 기능 하나로 여러개의 세션이 만들어진 것만으로도 이 기술이 얼마나 관심을 받고있는 것인지 느껴진다. Reactive 개발에 대한 관심도가 높은 근래에 계속 비동기 구현을 위한 기능들이 추가되는데 기존 코루틴에서 evaluated된 값을 전달하던 코루틴용 Stream인 Channel말고 추가로 비동기 객체 전달이 가능하고 코루틴에서 사용가능한 Stream인 Flow를 내놓았다. 이제 비즈로직에 코루틴을 활용한 한층 더 강화된 비동기 프로그래밍이 가능하게 되었다. 이것의 내용은 아직 블로그에 작성완료 못한 비동기 프로그래밍 2탄과 함께 다뤄서 작성하겠다.
DSL
개인적으로 코틀린하면서 코드 간결성의 끝판왕으로 느껴진 것은 brace만으로 코딩가능하게 해주는 DSL이었다. 기존에도 마지막 함수 인자를 함수로 받게 함수들을 구성하면 나만의 DSL을 만들어 주요 로직을 그 DSL로 만들 수 있었다. 하지만 그 파일 역시 코틀린 문법을 따라서 작성해야했기 때문에 뭔가 반쪽짜리 DSL이었는데, 나만의 확장자를 만들고 DSL정의 후 해당 DSL을 파싱할 수 있는 컴파일러 객체와 KotlinScript Annotation 기능을 이용해 연결하면 내 DSL파일이 Kotlin코드에서 사용가능한 객체로 전환이 가능하다. 이것을 통해서 각종 편의 기능들을 내가 직접 만들어 볼 수 있는 기회가 열렸다. 사실 세션을 들으면서 너무 멋진 기능이기에 kotlin기반의 나만의 DSL 언어를 하나 만들 수 있는 것 아닌가 하는 망상까지 해가며 혼자 즐거워했다. 역시 코틀린은 즐겨야해.
Space?
Kotlin 행사이지만 역시 Jetbrains와 강한 유착관계에있는 프로젝트인지라 Jetbrains의 Product lineup이 세션 하나를 할당해서 공개되었다. 바로 Space. Jetbrains가 기존에 가지고 있던 YouTrack, TeamCity등 개발팀 업무툴의 한계를 벗어나 업무용 메신져와 CI/CD, 회사 업무 전체를 위한 Project Mgt, Issue Tracker를 추가하고 모두 묶었다. 한마디로 Jetbrains product만 있으면 회사는 따로 더 이상 개발, 마케팅, 기획이 업무툴 분리 없이 다 같이 일할 수 있게 만들겠다는 거다. 뭐 데모는 훌륭했고 좋아 보였다. 문제는 가격인데 CI/CD 환경과 코드 Repository 운영까지 가능하게 다 포함되어 나쁘지 않은 가격처럼 보이기도 했다. 아직 Hosting으로만 제공되고 빠른 시일내에 설치형도 제공될 거라한다. 하지만 기존 업무 시스템을 여기로 넘겨야하는 기회비용이…너무.. 개인적으로는 다 넘어가면 개발자에게는 편할 것 같다. 특히 우리회사는 모든 업무 메신져가 카톡이다보니 일과 업무가 분할이 안되서..더더욱. 근데 여기에 놀라운 점이 한가지 있다. 굳이 이 프로덕트 발표를 Kotlin 컨퍼런스에서 하려고 했는가. 의 이유가 바로. Space는 3rd party application을 탑재할 수 있는 Platform이 되어 자체 Appstore가 존재할 거라 한다. 그리고 그 앱의 개발 언어가 KOTLIN!!! 새로운 업무툴 시장에 진입하기 위해서는 Kotlin을 써야한다는 거다. Kotlin개발자들에게는 잘하면 새로운 창업아이템을 선사하게될거같다. 문제는 Space Ecosystem이 얼마나 퍼질지가… 아무튼 Jetbrains를 좋게 생각하는 나는 팝콘들고 쳐다보다 나도 App을 만들어볼까? 하는 정도의 감상이었다.
내년에도 또?
사실 내년에도 열린다면 다시 오고 싶다. 언제나 그렇듯 이런 해외 컨퍼런스 특히, 기술 컨퍼런스를 다녀온 이후의 내 정신상태가 뽕맞은 것처럼 뭔가 원기 왕성해진다. 하고 싶은 것들이 줄줄이 생기고 깨닫는 것들이 많아 그 즐거움과 뿌듯함에 돈이 아깝지 않다. 이게 어찌보면 해외 컨퍼런스 참석을 다른 개발자분들에게 종용하는 이유일 것 같다. 대부분 영상 다시보기롤 볼 수 있는 거를 뭐하러 가냐고 하는데, 알고있지만 현장에서 챙겨듣지 않으면 집에서 잘 안보게된다. 그리고 그 현장에서 느껴지는 기술별 온도차 체험도 안되고. 역시 직접 가봐야한다. 이런 해외 컨퍼런스 자체의 욕구에다 아직 계속 학습 욕구가 불타는 Kotlin 관련 행사는 계속 참석해서 먼저 알고 싶다는 마음이다.
Recap은 끝.
내가 들었던 세션 리스트와 Youtube
Day 1
Day 2
|
|
----------------------------------------
"Review the KotlinConf 2019 Cophenhagen" 끝
----------------------------------------
|
|
퇴사 그리고 이직, 그 다음.
-
normal
-
2019 November 25
|
5년의 마침표..
2014년 11월, 레진에 합류하여 2019년 7월 퇴직때까지 거의 5년 이란 시간을 보내왔다. 레진의 기억은 사람으로 시작해서 사람으로 끝난 회사의 느낌이다. 레진에 입사하기로 마음 먹은 것도 레진의 구성원들이 너무나 좋았기 때문에 그 가운데 나도 들어가고 싶다라는 열망이 컸었고, 반대로 퇴사할 때는 내가 더 이상 누군가에게 자극을 줄 수 없는 퇴물이 되어버렸나..라는 자괴감(?)으로 인해 내 커리어의 불안함을 해소하고, 내가 줄 수 없으니 다시 다른 사람으로 부터 자극을 받고 싶었다. 언제나 그렇지만 난 나를 위한 결정들을 해왔다. 간혹 주변에서 나의 푸념을 듣고 너무 남을 위하는 것 아니냐 라는 말을 종종 듣는데, 사실 딱히 그렇지 않다. 나는 이기적이고, 역시 사람은 이기적인 것. 하지만 여러 가지 힘든 상황에 있는 팀을 두고 이직을 결심했을 때, 미안한 마음과 안타까움은 사실 아직도 쉽게 지워지지는 않는다. 이것은 시간이 지나야 해결될 것이고, 이전 회사가 내가 있을 때보다 더욱 잘되어서 내가 왜 퇴사했지? 라는 부러운 마음이 들도록 응원하는 것이 위선적인 위로일 것 같다. 일단 그래도 유명한 퇴사짤들 처럼. 마침표를 찍으니 후련했다.
이직 과정.
나이가 들수록 이직의 코스트는 상당하다. 새로운 분야로의 전환은 어렵고, 기존의 것들은 연차에 맞게 또는 상대의 기대수준에 맞게 높아야하며, 낮은 연봉은 가족에게 부담이 된다. 이런 복잡하고 힘든 상황에서도 이번 이직을 마음 먹기로하고 결정한 사항은 바로 “해외취업”이 었다. 이미 결론을 말하자면 해외취업은 실패했고, 현재의 회사에 합류하게 되었다. 우리 아이들의 나이가 더 많아기전에, 그리고 나의 기술력이 더 떨어지기 전에 적정한 몸값을 받을 수 있는 해외 회사로 나가려고 정말 많은 곳에 이력서를 제출하고 면접을 봤다. 지금 이야기지만 초반에 너무 대형회사에 시도한 것이 조금 작전 실패였다. 해외 면접의 연습을 좀 해보면서 도전했으면 결과가 다르지 않았을까 망상을 해본다. 해외 면접의 결과는 실패이지만 어찌보면 포기라고 볼 수도 있다.(정신승리) 거의 마지막에 진행된 캐나다의 A사 면접이 onsite까지 진행될 시점에 현실적인 이슈들을 정리하고자 와이프님과 이야기해보니, 우리 가족은 한국에서 살아야할 운명이었다. 조금 일찍이 알았더라면 힘들게 면접보고 시간을 쓰지 않아도 되었을껄 이라는 원망과 해외에 나가서 짊어져야할 가장의 불안감과 압박을 피해도 될 것 같다는 안도감이 동시에 밀려왔다. 복잡한 마음으로 이직의 목표가 사라졌다. 이때 살짝 멘탈이 나갔다. 그래도 이미 이직 패달을 밟아서인지 관성으로 멈출 수가 없었다. 레진에서 마음이 멀어져버렸다. 레진에서 기댈 수 있었던 선배가 떠난 다는 소식이 세간에 퍼지면서, 친분때문인지 많은 분들이 나 역시 이직해야하는 것 아니냐는 이야기와 분에 넘치는 자리들의 추천을 많이 해주셨었다. 어찌 보면 그냥 밍기적 거리면서 이직을 포기하려던 나의 멘탈에 불을 붙인 것일 수도 ㅋ. 그러던 와중에 투트랙으로 진행되었던 e사와 카카오가 최종합격을 하게 되었다. e사의 처우가 좋은 상황이었지만, 뼈때리는 선배 개발자 분의 조언으로 카카오로 이직 결정하게 되었다. 복잡한 생각들이 많았지만, 결정했다. 그래 가보자 카카오! 뭔가 슈퍼 개발자들에게 빨대를 꼽을 수 있을거야! 라는 마음으로!
휴식.
레진에는 e사의 최종합격때 퇴사 통보를 하였고 카카오는 퇴사하고 최종합격 통지를 받은 상황이었기에 카카오에 입사일자를 조정해. 인생의 마지막(?) 방학 3주를 보낼 수 있는 찬스를 얻었다. 하지만 여기서 이야기하는 것인데, 아이들이 있으신 분들 중 퇴사때 개인 시간을 보내고 싶은 분들은 방학시즌 퇴사는 비추합니다 ㅋ. 난 인생의 마지막 방학이 애들과 함께하는 방학이 되어 결국 아이들과 그 동안 바빠서 함께하지 못했던 시간을 충전하는 시간으로 보내졌다. 개인의 시간을 가지고 싶었던, 그리고 카카오에 가기전에 작은 프로젝트를 하나 마무리하고 싶었던 플랜은. 뻥 하고 터졌다. 사실 더 부지런하게 꼼꼼히 시간을 보냈다면 할 수 있었지만, 쉬는 시기에 그렇게 타이트한 시간 사용을 하고 싶지않았다. 그래도 아이들과 시간을 많이 보낸 것이 나중에는 절대 후회하지 않는 시간이었을 거라고 생각한다. 쉬는 동안에 그래도 틈틈이 한번 보자. 말로만 했던 주변 지인들을 많이 만나서 이야기 나누고, 그동안 뜸했던 오피스 투어를 쭉 돌면서 언제가 다시 뛰어들지 모르는 스타트업 세상에 연을 이어 놓았다. 3주란 시간 짧게 느껴졌지만 그래도 바쁘게 힐링을 했다.
첫 출근, 첫 업무
결국 그 날이 왔다. 이직 첫 출근. 어색한 마음에 신규인력 교육반에 들어가고 교육 끝에 버디(?)크루와 함께 정말 더 어색하고 묘하게 긴장되는 업무공간에 들어섰다. 아직 3개월 이란 시간 밖에 지나지 않아서, 아직도 업무공간에 들어가는 것에 떨림이 있지만 그 때는 더 떨렸다 ㅋ. 모든게 새롭고 생소한. 하지만 빨리 적응하고 싶었고, 빨리 뭔가 하고 싶었다. 왜냐! 들어오기전에 카카오에 기대한 것들이 컸기 때문에! 입사전에 카카오를 추천해주신 분의 이야기를 들어보니 재미있는 일들이 많이 있었다. 특히 팀에서 사용하는 기술 스택이 너무 내 취향이었기 때문에. 하지만 현실은 사뭇 달랐다. 현장은 현장이다. 레진과 마찬가지로 서비스를 운영하는 팀이다 보니 밀려오는 운영이슈와 신규 피쳐들의 구현. 어디선가 많이 보아왔던 업무 루틴들과 레거시. 거기에다 팀장이 날 뽑아놓고 떠난다는 소식과 첫 업무가… 전혀 생각지 못했던 Rails 업무까지. 살짝 당황했다. 역시 회사는 회사다. 뭐든 완벽한 곳은 없다. 그래도 내가 인복이 많아서 인지 팀원 분들이 너무 좋다. 여기 틈바구니 안에서 잘 자리 잡으면 롱런할 수 있을 것 같다.
그래서.. 내가 해야할.
롱런. 오래 다니기. 근데 내가 귀가 얇고 인내력이 좋지 못해 이런거 잘 못한다. 동기 부여가 떨어지면 또 힘든 결정을 하려들 것이다. 그래서 내가 이 팀에서 할일 들을 찾아서 동기부여가 떨어지지 않는 광맥들을 만들자고 생각했다. 근데 이미 팀에 엄청난 다이아몬드 레거시 광산이 자리잡고 있었다. 존재는 알지만 아무도 건드리지 않으려하는. 그래서 결정했다. 이 광산의 첫 곡괭이질을 내가 함으로써, 식지 않는 동기부여 광맥을 만들기로. ㅋ 어찌 보면 무모할 것도 같지만, 언젠가 누군가는 손을 데야할 것이라면 미루지말고 내가. 그리고 지금의 팀원들을 설득해서 합류시키면 팀에 큰 하나의 마일스톤을 함께 할 수 있는 기회가 생길거로 기대했다. 사실 그래서 아직 곡괭이질은 아니지만 갱도 설계 계획을 팀에 공유했다. 아마 팀원분들이 미심쩍고 불안해할 수 있지만, 혼자가 아니라 같이하면 잘 될거라 생각한다. 이거 붙들고 있으면 시간이 진짜 총알 같이 갈거다. 할거가 너무 많아서 ㅋㅋ. 벌써 재미있고 기대된다.
누가 이 후기겸 일기를 볼지는 모르겠지만, 나 처럼 동기부여 계속 만들며 자기 채찍질하는 것을 좋아하시는 분이 있다면 아래의 공고로 팀에 지원하시길. 듣기로는 T/O가 열려 있는 모양이다.
카카오톡 서버 개발자 모집
팀원분들에게 나의 계획에 참여할 수 있도록 추가 발표자료들을 만들어야한다. 지금도 코드랩을 짜다가 회고를 너무 미루면 못쓸 것 같아 휴식겸 넋두리. 지난달에 회고를 남겨야겠다고 생각했을 때는 쓸 이야기들이 머리속에 가득이었는데, 하루가 다르게 머리가 나빠져 다 까먹었다. 두서없는 나의 일기 회고는 여기서 후다닥 마무리한다.
광맥 프로젝트가 자리를 잡을 시점에 공유해보자.
|
|
----------------------------------------
"퇴사 그리고 이직, 그 다음." 끝
----------------------------------------
|
|
project 100
-
normal
-
2019 October 29
|
도전 Projects 100!
이게 뭐냐하면 지속적인 학습을 위해 시작하는 프로젝트로 일단 하루에 하나의 알고리즘 문제를 풀어보자는 취지. 사실은 @sjpark이 leetcode 100개 풀었다는 이야기와 카카오에서 진행하는 프로젝트100을 보고 따라하는 개인 toy project. projects로 복수인 것도 이번에는 알고리즘이지만 다음번에는 다른걸로!
Projects 100의 첫 번째!
위에 말한 것 처럼 매일 하나의 알고리즘 문제를 풀자.
아래와 같은 Ground Rule도 있다!
- easy만 풀자
- 메인 언어가 아닌 언어로 풀자
어차피 하기로 한거 조금이라도 도움이 되기위해. easy로만 하는 이유는 혹여나 나의 귀차니즘이 난이도를 넘어서면 이 프로젝트가 깨질까봐.
일단 시작한 프로젝트니 한 번은 끝까지 이끌어가기 위함이다.
진행 중인 프로젝트의 repo는 여기를 구경하면 된다.
One more thing
사실 이 글도… 죽어있는 블로그의 health check 정도의 글. ㅋ
|
|
----------------------------------------
"project 100" 끝
----------------------------------------
|
|
