|
OpenTracing? OpenTracing!
- 2020 February 26 OpenTracing? 넌 누구니. 왜 필요하니.이제는 대부분 서비스들에게 분산 인프라 환경이 보편화되면서 복잡도를 가지게된 인프라 환경의 모니터링과 운영 이슈 처리에 관심을 많이 가진다. 그래서 분산 환경에서의 디버깅용 로깅을 어떻게 하면 좋을까 찾다가 알게된 OpenTracing에 대해 정리해보았다. OpenTracing이란이 공유에서 언급될 OpenTracing은 CNCF 산하의 프로젝트로 단어 그자체 처럼 하나의 흐름을 공개적으로 추적하기 위한 기능을 표준화하는 프로젝트입니다. 아직 공식적인 OpenTracing의 표준은 존재하지 않고 CNCF가 가장 큰 기구이기 떄문에 Cloud환경의 입김(question)이 쎄서 주목받는 비공인 표준 입니다. 현재 해당 OpenTracing spec을 기준으로 만들어지는 Tracer들로는 Zipkin, Jaeger, Lightstep등 다양하게 존재합니다. (CNCF사이트 supported tracer목록에 zipkin이 빠져있는건 왜 그런지 궁금하네요) 이제는 서비스를 운영하는 대부분의 서버 개발자들에게 MSA가 보편화되고 여러 효율성 관점에서 도입되고 있을 때, 이런 분산 환경의 로깅이 주목을 받으며 OpenTracing이 그 방안으로 나오고 있습니다. 사실 OpenTracing은 분산 환경의 로깅을 목적으로 만들어진 것이 아니고 하나의 request에서 response를 반환 할 때까지 거치는 서버의 연결 점들을 추적하기 위한 시스템으로 시작된 것이었습니다. 이 서버 연결을 추적하다보니 자연스럽게 해당 서버들의 req/res latency를 확인할 수 있게되어 bottleneck check가 가능하게 되고 그 서버 안의 로그까지 합쳐져 코드레벨의 디버깅도 할 수 있는 기능들도 들어가게되었습니다.
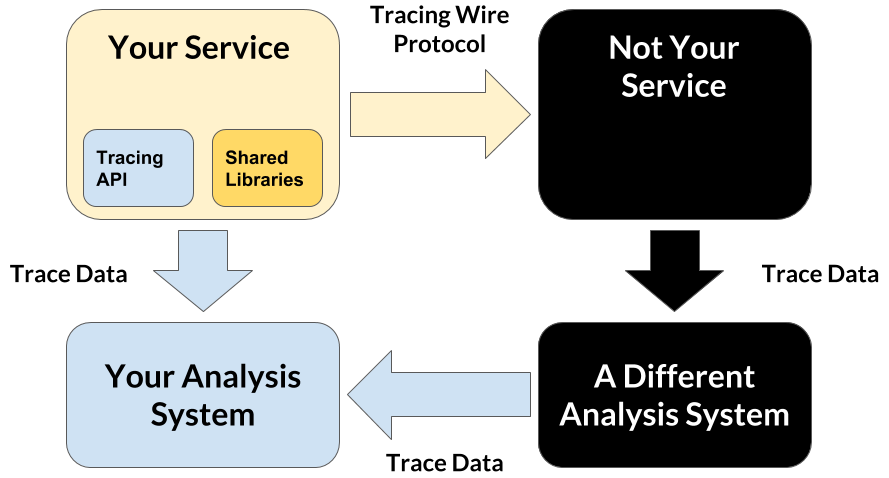
표준화를 시도하는 이유는 OpenTracing Big Piceces(위 그림)에도 설명되어있지만 OpenTracing이 표준화된다면 우리 서비스의 분산 로깅만 가능한 것이 아니라 우리 서비스에서 외부서비스로 연결시 최초 요청의 trace id로 연결되어 모든 연결 구조의 추적이 가능하게 됩니다. 예를 들어 빌링 서비스도 우리가와 모두 같은 tracer 기준으로 opentracing 을 설정한다면 장애발생시 좀 더 빠르게 확인이 가능하곘죠? :-) 왜 OpenTracing을 갑자기?현재 (회사)팀의 환경에서 운영중인 서버가 단일 서버군을 참조하는 것이 아니고 요청에 따라 복수개의 서버군을 거치게 됩니다. 이럴 때 서버간 로그가 통합관리되는 것이 아니라 문제에 대한 디버깅시 로그를 각자 찾거나 bottleneck을 찾기하는 활동을 할때 각 서버의 로그들을 따로 뒤져봐야하는 불편함이 있습니다. 거기에다 각 서버별 로그를 연결된 reqeust/response를 찾아서 보는 것이 정말 쉽지 않은 일입니다. 앞으로 팀에서 관리하는 서버군의 복잡도가 올라가고 분산 환경이 더 커지게 될 수록 디버깅 작업의 난이도가 올라가고 개발자의 피로도가 올라갈 것이 예상되기 때문에 이러한 작업이 진행되면 차후 편안한 디버깅 생활을 할 수 있을 것 같아 도입검토가 필요합니다. 물론 디버깅할 일이 없게 코딩을 잘하면 좋겠지만 현실은….ㅋ. 최근 팀에서 검토중인 istio가 팀에 녹아들거나 한다면 더욱 편하게 OpenTracing환경을 도입할 수 있게됩니다. OpenTracing OverviewOpenTracing spec에 대해서 간단하게 오버뷰를 해봅니다. 우선 OpenTracing에서 사용하는 Data Model들을 먼저 이해하면 관련 문서를 참조시 도움이 될거라 간단하게 짚어봅니다.
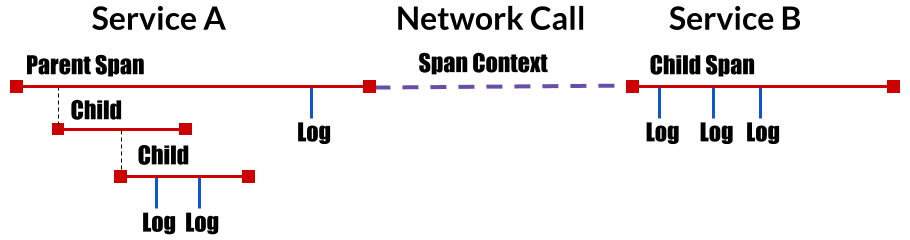
동작 원리동작 원리는 의외로 간단합니다. 위에서 설명한 Span단위의 정보들을 특정 Storage서버에 전달하면 해당 시스템은 그 Span들을 Trace ID, Span ID별로 Timestamp 정렬하게 됩니다. Tracer 별로 SpanContext 구조나 형태가 다를 수 있어 Tracer별로 서로 Span을 공유하지는 못하고 컨버터들이 존재는 합니다 Zipkin Example Flow - https://zipkin.io/pages/architecture.html OepnTracing을 통해 우리팀이 얻을 수 있는 것
OpenTracing을 통해 해야할 일이렇게 좋은 것을 왜 이제야! 그리고 왜 다른 곳은 안하지? 에 대해 고민해보면 답은 사실 간단합니다. 인프라 구조가 복잡도 + 디버깅의 어려움 vs 환경 구성에 대한 불편함 의 내적 대결 구조가 있기 때문입니다. OpenTracing 환경 구성을 위해서는 처음 설정에 노오오오력이 들어갑니다. 세상에 쉬운일은 없습니다. 하지만 조금 노오오오오력 해서 구성하면 후세에 편안함이 올거라 생각됩니다. 그래서 할일을 나열해보면…
끗 |