
|
구글 클라우드 데이터스토어에서 스트롱 컨시스턴시와 이벤츄얼 컨시스턴시의 균형잡기
- 2016 April 03 구글 클라우드 데이터스토어에서 스트롱 컨시스턴시와 이벤츄얼 컨시스턴시의 균형잡기
원문 : Balancing Strong and Eventual Consistency with Google Cloud Datastore
일관성있는 사용자 경험의 제공과 이벤츄얼 컨시스턴시(Eventual Consistency) 모델을 활용한 대형 데이터셋 확장법이 글에서는 구글 클라우드 데이터스토어의 이벤츄얼 컨시스턴시 모델로 대량의 사용자와 데이터를 처리하면서 스트롱 컨시스턴시의 장점을 얻을 수 있는 방법을 다룹니다. 이 문서에서는 구글 클라우드 데이터 스토어로 솔루션을 만들기를 원하는 소프트웨어 아키텍터와 개발자들을 위해 쓰여졌습니다. 구글 데이터 스토어 같은 비관계형 시스템 보다 관계형 데이터베이스에 더 익숙한 독자들을 위해, 이 문서에서는 관계형 데이터베이스와 유사한 컨셉들을 알려드립니다. 문서에서는 여러분들이 구글 클라우드 데이터 스토어에 기본적으로 친숙하다고 가정하고 있습니다. 구글 클라우드 데이터 스토어를 시작하는 가장 쉬운 방법은 파이썬,자바,고,PHP를 지원하는 구글 앱엔진을 이용하는 것 입니다. 만약 앱엔진을 아직 사용해본적이 없다면, 먼저 앱엔진 지원 언어 중 하나로 시작 안내서와 데이터 저장 세션을 우선 읽어보길 권장합니다. 샘플 코드들이 파이썬으로 되어있더라도 이 문서를 따라오는데에 파이썬 언어에 대한 전문성은 필요하지 않습니다. Concepts
NoSQL 과 이벤츄얼 컨시스턴시NoSQL 데이터베이스로 알려진 비관계형 데이터베이스가 근래에 관계형 데이터 베이스의 대체제로 사용되고 있습니다. 구글 클라우드 데이터스토어는 업계에서 가장 널리 사용되는 비관계형 데이터베이스중에 하나입니다. 2013년에는 한달에 45조번의 트랜젝션이 처리되었습니다(구글 클라우드 플랫폼 블로그). 데이터스토어는 개발자들에게 데이터를 저장하고 접근하는 단순화된 방법을 제공합니다. 또한 초대형 시스템에서의 고성능, 고신뢰성 등의 관계형 데이터베이스에서 최적화되지 않는 여러 기능들을 제공합니다. 관계형 데이터베이스에 더 익숙한 개발자들에게는 비교적 덜 친숙한 비관계형 데이터베이스의 몇몇 특성들과 동작들 때문에 아마도 비관계형 데이터 베이스로 시스템을 디자인 하는 것은 쉽지 않을 것입니다. 비록 구글 클라우드 데이터스토어 프로그래밍 모델은 단순하지만, 이것의 특성들을 깨닫는 것은 매우 중요합니다. 이벤츄얼 컨시스턴시가 이러한 특성들 중 하나입니다. 그리고 이벤츄얼 컨시스턴시를 위한 프로그래밍이 이 문서의 주제입니다. 이벤츄얼 컨시스턴시(Eventual Consistency)란 무엇인가?이벤츄얼 컨시스턴시는 이론적으로 엔티티에서 발생하는 새로운 변경사항이 적용되지 않은 상태로 제공되었다가 결국에는 최종 업데이트 값이 반환되는 것을 보장합니다. 인터넷 도메인 네임 시스템(DNS)은 이벤츄얼 컨시스턴시 모델의 잘 알려진 예제입니다. DNS 서버들은 최신 값들을 반영할 필요는 없지만 인터넷상의 많은 지역에 걸쳐 값들을 캐쉬하고 복제합니다. 모든 DNS 클라이언트와 서버에 면경된 값들을 복제하는 것에는 특정 시간이 걸립니다. 하지만 DNS 시스템은 인터넷의 기반 중 하나로 아주 성공적인 시스템입니다. 전체 인터넷에 걸쳐 수억개의 디바이스들 위에서 주소 찾기가 가능한 것은 이 시스템이 고가용성을 가지고 있고 아주 확장적이란 것을 뜻합니다. 그림 1은 이벤츄얼 컨시스턴시에서 복제의 컨셉을 그린 것입니다. 다이어그램은 복제품들이 항상 읽기가 가능하지만 몇몇 복제품에서는 원본에 쓰여진 최신내용과 다를 수 있다는 것을 보여줍니다. 다이어그램에서 노드A는 원본 노드이고 노드B와C는 복제품입니다.
그림 1: 이벤츄얼 컨시스턴시에서의 복제 컨셉 묘사 반대로 전통적인 관계형 데이터베이스들은 스트롱 컨시스턴시(Strong Consistency) 또는 이미디어트 컨시스터시(Immediate Consistency)로도 불리우는 컨셉을 기반으로 디자인 되었습니다. 이 말은 데이터가 변경된 것이 바로 엔티티의 모든 관찰자에게 보여지는 것을 말합니다. 이 특성은 관계형 데이터베이스를 사용하는 많은 개발자들에게 기초적인 가정이었습니다. 그러나 스트롱 컨시스턴시를 사용하기 위해서 개발자들은 그들의 어플리케이션의 확장성과 성능에 관하여 반드시 타협해야만 했습니다. 간단한 삽입을 할 때도 데이터가 수정되고 복제되는 동안, 어떠한 프로세스도 같은 데이터를 수정하지 못하도록 잠겨집니다. 스트롱 컨시스턴시의 배포 방법과 복제 과정에 대한 컨셉 뷰는 그림2와 같습니다. 이 다이어그램에서 여러분들은 어떻게 원본 노드가 항상 복제품들과 일관성을 유지하는 지와, 수정이 완료될 때 까지 노드에 접근이 불가능하다는 것을 알 수 있습니다.
그림 2: 스트롱 컨시스턴시에서의 복제 컨셉 묘사 스트롱 컨시스턴시(Strong Consistency)와 이벤츄얼 컨시스턴시(Eventual Consistency) 균형 맞추기최근 비관계형 데이터베이스가 높은 확장성과 고가용성 성능을 필요로하는 웹어플리케이션에서, 특히 인기를 얻고 있습니다. 비관계형 데이터베이스는 개발자들에게 각 어플리케이션에서 스트롱 컨시스턴시와 이벤츄얼 컨시스턴시 사이에서 최적의 균형을 선택하게 합니다. 이것은 개발자들에게 두 세계의 장점을 결합할 수 있도록 합니다. 예를 들어, “현재 접속한 친구를 알아내는 것”, “얼마나 많은 사용자들이 여러분의 글에 +1을 했는지 알아내는 것”과 같은 정보는 스트롱 컨시스턴시를 사요할 필요가 없습니다. 이러한 경우에는 이벤츄얼 컨시스턴시를 통해 확장성과 성능을 얻을 수 있습니다. 스트롱 컨시스턴시를 사용해야하는 경우는 “결제과정이 종료된 사용자인지 아닌지”, “게임 플레이어가 전투세션에서 획득한 점수가 몇인지” 등과 같은 정보를 포함한 경우 입니다. 아주 많은 엔티티들을 가진 사례를 일반적으로 생각해보면, 이벤츄얼 컨시스턴시가 최고의 모델로 자주 언급이됩니다. 하나의 질의문 안에 아주 많은 결과들이 들어있더라도, 이때 사용자는 특정 엔티티들의 포함 또는 제외에 의한 영향을 느끼지 못할 것입니다. 한편, 소수의 엔티티들과 작은 컨텍스트의 사례에서는 스트롱 컨시스턴시가 필요하다고 생각되어집니다. 컨텍스트가 엔티티들이 포함되거나 제외되는 것을 사용자가 인식하도록 할 것이기 때문에, 사용자들은 영향을 느끼게 될 것입니다. 이러한 이유들 때문에, 개발자들이 구글 클라우드 데이터스토어의 비관계형 특성들을 이해하는 것은 매우 중요합니다. 뒤의 세션들에서는 이벤츄얼 컨시스턴시와 스트롱 컨시스턴시 모델들을 확장가능하고 고가용성, 고성능 어플리케이션을 만들때 어떻게 섞어 사용할 지에 대하여 이야기합니다. 이를 통해, 긍정적인 사용자 경험을 위한 컨시스턴시 요구사항들을 만족시킬 수 있을 것입니다. 구글 클라우드 데이터스토어에서의 이벤츄얼 컨시스턴시(Eventual Consistency)데이터에 대한 강력한 일관성이 필요한 상황에서는 반드시 그에 맞는 API를 선택해야합니다. 다양한 종류의 구글 클라우드 데이터스토어 질의 API들과 그에 해당하는 컨시스턴시가 <표 1>에 정리되어 있습니다.
표 1: 구글 클라우드 데이터스토어의 질의호출들과 그에 해당하는 컨시스턴시 동작들 구글 클라우드 데이터스토어에서 엔세스터 없는 쿼리들은 글로벌 쿼리문(Global Query)으로 알려져있고 이벤츄얼 컨시스턴시로 동작하도록 디자인되어있습니다. 글로벌 쿼리문은 스트롱 컨시스턴시를 보장하지 않습니다. keys-only 글로벌 쿼리는 쿼리에 해당하는 엔티티들의 속성값들을 포함하는 것이 아니라 키들만(key-only) 반환하는 쿼리입니다. 엔세스터 쿼리(Ancestor Query)는 엔세스터 엔티티를 기반한 쿼리를 말합니다. 뒤에서 각 컨시스턴시 동작들에 대하여 더 자세히 다룹니다. 엔티티(Entity)를 읽는 시점의 이벤츄얼 컨시스턴시(Eventual Consistency)엔세스터가 빠진 쿼리에서는 수정된 엔티티가 쿼리 실행 시점에 바로 보여지지 않을 수 있습니다. 엔티티들을 읽을 시점의 이벤츄얼 컨시스턴시 영향을 이해하기위해, Score 속성을 가진 Player 엔티티가 하나 있는 시나리오를 생각해 봅시다. Score는 초기 값으로 100을 가졌다고 합시다. 얼마후 Score가 200으로 수정되었습니다. 만약 글로벌 쿼리가 실행이 되었고 이 결과에 위의 Player 엔티티가 포함되어있다면, 반환된 엔티티의 Score 값이 수정 전의 100일 가능성이 있습니다. 이 동작은 구글 클라우드 데이터스토어 서버간의 복제로 인해 발생합니다. 복제는 구글 클라우드 데이터스토어 기반 기술들인 Bigtable, Megastore에 의해서 관리됩니다(추가자료에 Bigtable과 Megastore 관련 자세한 정보가 있습니다). 복제본들의 과반이상이 수정요청을 인식될 때까지 동기적으로 대기하는 Paxos 알고리즘으로 복제는 실행됩니다. 복제본 엔티티는 변경 요청으로부터 일정 시간뒤에 데이터에 반영됩니다. 이 시간은 일반적으로 작지만, 실제 길이에 대해 어떤 보장도 되지 않습니다. 변경이 완료되기전에 요청된 쿼리는 아마도 변경전 데이터를 읽어갈 것입니다. 대부분의 경우에, 모든 복제본으로의 변경사항 전달은 매우 빠를 것 입니다. 하지만 몇몇 요소들이 함께 섞여 일관성 확보를 위한 시간이 증가할 수도 있습니다. 이러한 요소들에는 많은 서버들을 가진 데이터센터 전체가 데이터센터간 교체 상항들도 포함됩니다. 이러한 요소들의 다양함 때문에, 완벽한 일관성 수립을 위한 특정 시간을 보장하는 것은 불가능합니다. 최종값을 반환하는 쿼리를 위한 필요 시간은 일반적으로 매우 짧습니다. 그러나 드물게 복제 대기 시간이 증가되는 경우, 그 시간은 더 길어질 수 있습니다. 구글 클라우드 데이터스토어를 사용하는 어플리케이션들은 이러한 상황들이 잘 처리될 수 있도록 글로벌 쿼리 디자인을 신중히 해야합니다. 엔티티를 읽을 때의 이벤츄얼 컨시스턴시는 keys-only 쿼리, 엔세스터 쿼리, (get() 메소드를 이용한는) key를 이용한 쿼리를 통해 피할 수 있습니다. 뒤에서 이런 다른 형태의 쿼리들에 대하여 알아봅니다. 인덱스를 읽을 시점의 이벤츄얼 컨시스턴시(Eventual Consistency)글로벌 쿼리가 실행될때 아마도 인덱스는 아직 변경되지 않았을 것입니다. 이 말인 즉슨 반환된 엔티티들의 최종 변경값은 읽을 수 있더라도, 반환된 “엔티티 목록” 결과는 아마도 이전 인덱스 값에 의해 만들어진 것일 수 있습니다. 인덱스를 일을때의 이벤츄얼 컨시스턴시의 영향을 이해하기 위해, Player라는 새 엔티티 하나가 구글 클라우드 데이터 스토어에 삽입되는 시나리오를 상상해봅시다. Player 엔티티는 Score란 속성을 가지고 있고 초기값은 300입니다. 삽입 후 바로, Score가 0보다 큰 모든 엔티티들을 반환하는 keys-only 쿼리를 실행한 다고 합시다. 당연히 방금 삽입한 Player 엔티티가 반환될 것이라고 기대할 것 입니다. 하지만 기대와는 달리 Player 엔티티가 결과에 포함되지 않았다는 것을 알 수 있을 겁니다. 이 상황은 쿼리하는 시점에 Score 인덱스테이블이 새로 삽입된 값을 반영하지 못했을 때 발생할 수 있습니다. 구글 클라우드 데이터스토어의 모든 쿼리들은 인덱스 테이블을 통해 실행된다는 점을 기억해야합니다. 그리고 아직도 인덱스 테이블의 변경은 비동기로 처리되고 있습니다. 특히 모든 엔티티의 수정은 두 단계로 구성되어 있습니다. 실행하는 단계인 첫번째 단계에서는 트랜젝션(Transaction) 기록을 작성하는 것이 수행됩니다. 두번째 단계에서는 데이터가 쓰여지고 인덱스들이 변경됩니다. 만약 첫번째 단계가 성공햇다면, 데이터 작성단계가 즉시 실행되지는 않더라도 성공할 것을 보장받게 됩니다. 만약 인덱스들이 변경되기 전에 엔티티를 조회하면 변경되기 이전의 값을 보게 될 것 입니다. 두 단계의 처리 과정 때문에 글로벌 쿼리에서 변경된 값이 보여지기 전까지 시간 딜레이가 생기게 됩니다. 이러한 엔티티 값의 이벤츄얼 컨시스턴시에 의한 시간 딜레이는 일반적으로 작지만 (심지어 몇분 또는 예외적 상황에서 그 이상으로) 길어질 수 도 있습니다. 다음과 같은 변경들 뒤에서도 동일한 상황이 발생할 수 있습니다. 예를 들어 이미 존재하는 Player 엔티티의 Score를 0으로 변경하고, 바로 동일한(Score가 0보다 큰 엔티트를 반환하는) 쿼리를 실행했다고 합시다. Score가 0으로 변경되었기 때문에 아마도 엔티티가 포함되지 않을 거라고 기대하지만 비동기 인덱스 수정 동작 때문에 여전히 포함되어 있을 것입니다. 인덱스를 읽을 때의 이벤츄얼 컨시스턴시를 피하기 위한 방법으로는 엔세스터 쿼리를 사용하거나 key로 찾는 방법 뿐입니다. keys-only 쿼리는 이 동작을 피할 수 없습니다. 엔티티와 인덱스를 읽을 때의 스트롱 컨시스턴시(Strong Consistency)구글 클라우드 데이터스토어에서는 엔티티와 인덱스를 위한 강력한 일관성을 보장하는 방법으로는 (1) key를 이용해서 찾는 방법과 (2) 엔세스터 쿼리, 오직 이 두가지 API만을 제공합니다. 만약 어플리케이션 로직이 스트롱 컨시스턴시를 요구한다면 개발자는 반드시 이 방법중 하나를 사용해 구글 클라우드 데이터스토어의 엔티티들을 읽어야 합니다. 구글 클라우드 데이터스토어는 이 API들을 통해 스트롱 컨시스턴시가 제공되도록 디자인되어 있습니다. 이 중에 하나를 호출하게 되면, 구글 클라우드 데이터스토어는 복제본 중 하나와 인덱스 테이블에 밀린 모든 변경사항들을 처리한 뒤에 키를 통한 조회 또는 엔세스터 쿼리를 실행할 것입니다. 그래서 변경된 인덱스 테이블을 통한 최신 엔티티 값은 항상 마지막 변경을 포함한 값들을 반환할 것입니다. 쿼리들과는 반대로 키를 통한 호출은 오직 한 개의 엔티티 또는 키에 맞는 엔티티 묶음 또는 키들의 묶음 만을 반환합니다. 이 말은 엔세스터 쿼리만이 구글 클라우드 데이터스토어에서 스트롱 컨시스턴시 조건과 필터 조건을 충족시킬 수 있는 유일한 방법이란 것 입니다. 하지만 엔세스터 쿼리는 엔티티 그룹을 지정하지 않고서는 동작하지 않습니다. 엔세스터 쿼리(ancestor Query)와 엔티티 그룹(Entity Group)이 문서 처음에 이야기했던 것 처럼, 구글 클라우드 데이터스토어의 장점 중 하나는 개발자가 스트롱 컨시스턴시와 이벤츄얼 컨시스턴시의 최적 균형을 조절할 수 있다는 것입니다. 구글 클라우드 데이터 스토어에서 엔티티 그룹은 스트롱 컨시스턴시, 트렌젝션, 지역성(locality)의 단위입니다. 엔티트 그룹들을 구성함으로써 개발자들은 어플리케이션내 엔티티들 사이의 스트롱 컨시스턴시 범위를 지정할 수 있습니다. 이러한 방법으로 어플리케이션은 전체 시스템에서 고확장성, 고가용성, 고성능을 얻는 동시에 엔티티 그룹 내부의 일관성을 조절할 수 있습니다. 엔티티 그룹은 루트 엔티티와 자식들 또는 후임들로 이루어진 계층 구조입니다.[1] 엔티티그룹을 생성하려면 기본적으로 개발자는 일련의 부모키와 하위키로 이루어진 엔세스터 패스를 지정해야합니다. 엔티티 그룹의 컨셉은 그림3처럼 그려집니다. 이 경우에는 “ateam”인 루트키가 “ateam/098745” 와 “ateam/098746”로 설정된 키를 가진 두개의 자식들을 가지고 있습니다.
엔티티그룹 내부에서는 다음과 같은 점들이 보장됩니다. :
엔세스터 쿼리는 유일하게 특정 엔티티그룹에 대하여 수행할 수 있는 특별한 쿼리입니다. 엔세스터 쿼리는 스트롱 컨시스턴시로 동작합니다. 구글 클라우드 데이터스토어는 모든 정체된 복제와 인덱스 변경이 엔세스터 쿼리 수행전에 적용되는 것을 보장합니다. 엔세스터 쿼리(Ancestor Query) 예제이 부분에서는 엔티티 그룹과 엔세스터 쿼리를 사용하는 방법에 대하여 실습해봅니다. 뒤에 나오는 예제에서 우리는 사람들에 대하여 기록된 데이터를 관리하는 문제를 고려해봅니다. 특정 종류(Kind)에 엔티티를 추가하자마자 해당 종류의 쿼리를 실행하는 코드가 있다고 가정해봅시다. 아래의 파이썬 예제 코드를 통해 이 컨셉을 확인해봅니다. 대부분의 경우, 이 코드의 문제는 바로 위 명령에서 추가된 엔티티가 반환되지 않는 다는 것입니다. 삽입 이후에 바로 뒷 줄에서 실행되는 쿼리들은 실행되는 시점에 인덱스가 변경되지 않았을 것입니다. 그러나 이런 경우에 또 다른 타당성 문제가 있습니다. 전환없이 한페이지에 모든 사용자 목록을 가져올 필요가 있을까요? 만약에 그 수가 백만이라면? 아마도 페이지를 표시하는데 너무 많은 시간이 걸릴 것입니다. 사용성의 본질은 쿼리 범위를 좁힐 수 있는 일부 내용만을 제공하도록 하는 것입니다. 이 예제에서 우리가 사용하게될 부분은 GqlQuery상으로 엔세스터 멤캐쉬(Memcache)와 클라우드 데이터스토어(Cloud Datastore)간 일관성 유지엔티티 그룹은 멤캐쉬 엔트리들과 구글 클라우드 데이터스토어 엔티티들 간의 일관성을 유지하는 하나의 단위로도 사용됩니다. 예를 들어 각 팀 별 엔티티 그룹(Entity Group)과 엔세스터 쿼리(Ancestor Query)의 한계들엔티티 그룹과 엔세스터 쿼리를 사용하는 방식이 만병통치약은 아니다. 아래 목록에 나온 것처럼 기술을 일반에 적용하는 것에는 실제로 2가지 어려움이 따릅니다.
쓰기 한계중요한 부분은 시스템은 반드시 각 엔티티 그룹안의 수정(또는 트랜잭션) 횟수를 고려해서 디자인 되어야한다는 것 입니다. 공유된 한계는 엔티티 그룹당 1초에 하나의 업데이트 입니다.[2] 만약 한계를 초과한 수정 횟수가 필요하게되면 엔티티 그룹은 퍼포먼스 버틀넥이 될 수 있습니다. 위 예제에서 각 엔티티그룹 관계들의 불변성두번째 도전은 엔티티그룹 관계들의 불변성입니다. 엔티티그룹 관계는 키 이름을 기반해서 정적으로 고정되어 있습니다. 엔티티를 생성한 다음에는 변경될 수 없습니다. 관계를 바꿀 수 있는 유일한 방법은 엔티티 그룹안의 엔티티들을 삭제하고 다시 생성하는 것 입니다. 이 도전은 엔티티 그룹을 컨시스턴시 또는 트랜젝션을 위한 ad-hoc 범위로 정의하고 사용하는 것을 막습니다. 대신 컨시스턴시와 트랜젝션 범위는 디자인시에 정의된 정적 엔티티 그룹과 거의 동일합니다. 예를들어, 두 개의 은행계좌 사이의 유선 이체를 구현하려는 시나리오를 생각해봅시다. 이 작업 시나리오는 스트롱 컨시스턴시와 트랜젝션이 필요합니다. 그러나 두 계좌들은 하나의 엔티티 그룹으로 엮을 수 없고 또 광역 부모에 기반할 수 도 없습니다. 그 엔티티그룹에 계좌 이체가 수행되게 되면 다른 계좌 이체 요구들을 처리하는 전체시스템에 버틀넥을 만들 것 입니다. 그래서 엔티티그룹은 이러한 방식으로 사용될 수 없습니다. 하지만 고확장성과 고가용성이 가능하도록 구현된 계좌이체를 위한 대체방법이 있습니다. 이 요구사항을 만족하는 한가지 방법은 크로스그룹(Cross-group : XG) 트랜잭션과 구글 클라우드 데이터스토어의 키검색 또는 엔세스터쿼리를 사용하는 것 입니다. 크로스그룹 트랜잭션은 하나의 트랜젝션안에서 최대 25개의 엔티티그룹 또는 엔티티에 대하여 ACID 특성을 가질 수 있게 해주는 구글 클라우드 데이터스토어 기능입니다. 크로스그룹 트랜잭션을 사용함으로써 요청을 처리하는 시점에 두개의 은행 계좌에 대한 트랜잭션 범위를 동적으로 정의할 수 있습니다. 크로스그룹 트랜잭션은 단지 트랜잭션 보장만 한다는 것을 명심해야합니다. 두 개의 은행계좌를 읽을때 스트롱 컨시스턴시를 확보하기위해 반드시 키검색 또는 앤세스터쿼리를 사용해야합니다. 트랜잭션 안에서 앤세스터쿼리를 사용하지 않고 쿼리 실행을 시도하면 애러가 발생합니다. 엔세스터 쿼리의 대체제들만약 여러분이 이미 구글 클라우드 데이터 스토어에 많은 숫자의 엔티티들을 저장한 어플리케이션을 가지고 있다면, 리펙토링을 통해 엔티티그룹을 분리하는 것은 힘들 것 입니다. 그러기 위해서는 모든 엔티티들을 삭제하고 엔티티 그룹 관계에 그것들을 추가하는 것이 필요할 것입니다. 그래서 구글 클라우드 데이터스토어를 위한 데이터 모델링에서는 어플리케이션 디자인 전반부에 해당하는 엔티티 그룹 디자인할 때의 결정이 중요합니다. 그렇지 않으면 특정 레벨의 컨시스턴시를 얻기 위해 키 검색을 통한 키 쿼리 또는 멤캐쉬를 이용하는 것 같은 대체 방식으로 리펙토링시에도 한계가 있을 것입니다. Key를 통한 조회(Lookup by key) 뒤의 키전용 전역 쿼리키전용 전역 쿼리는 엔티티들의 속성 값을 제외하고 단지 키들만 반환하는 특별한 형태의 전역 쿼리입니다. 반환되는 값들이 단지 키들뿐이기 때문에 이 쿼리는 엔티티 값에서 발생할 수 있는 컨시스턴시 문제가 나타나지 않습니다. 키전용 옵션과 전역 쿼리의 조합은 lookup method와 함께 최신 엔티티 값들을 읽을 것입니다. 하지만 하나의 엔티티도 반환하지 못한 결과를 가 발생할 수 있는 키전용 전역 쿼리는 쿼리하는 시점에 아직 인덱스가 일관성을 갖추지 못하고 있었을 가능성을 배제할 수 없다는 것을 반드시 인지하고 있어야합니다. 쿼리의 결과는 잠재적으로 이전 인덱스 값들로 필터되어 생성되었을 수 있습니다. 요약하면, 개발자는 어플리케이션이 인덱스 일관성이 유지않아도되는 시점에서만 키 조회 뒤의 키전용 전역 쿼리를 사용해야 할 것입니다. 멤캐쉬(Memcache) 사용하기멤캐쉬 서비스는 휘발성이지만 아주 일관적입니다. 그래서 멤캐쉬 검색과 구글 클라우드 데이터스토어 쿼리들의 결합에 의해 일관성 문제를 최소화할 수 있는 시스템을 만드는 것이 가능합니다. 예를 들어, 0보다 큰 점수를 가진
캐쉬된 목록이 멤캐쉬에 존재할 때는 언제나 반환된 목록은 일관적일 것입니다. 만약 캐쉬 데이터가 사라지게되거나 멤캐쉬 서비스가 일시적으로 사용할 수 없다면, 시스템은 아마도 구글 클라우드 데이터스토어에서 일관성 확보가 되지 않았을 가능성이 있는 결과를 읽어야할 수 밖에 없을 것 입니다. 이 방식은 적은 양의 오차를 견뎌내는 모든 시스템에 적용될 수 있습니다. 구글 클라우드 데이터 스토어의 캐싱 레이어로써 멤캐쉬를 사용하는 몇가지 최고의 예제가 있습니다.
엔티티 그룹으로의 점진적 마이그레이션이전 세션에서는 단지 비일치 가능성을 줄이는 방향으로 제안되어져 있었습니다. 스트롱 컨시스턴시가 필요할 때는 엔티티 그룹과 엔세스터 쿼리를 기반으로 어플리케이션을 디자인 하는 것이 최선입니다. 하지만 기존의 어플리케이션이 기존의 데이터 모델을 변경해야하고 어플리케이션 로직을 전역 쿼리에서 엔세스터 쿼리로 변경해야하는 것을 포함하는 경우의 마이그레이션에는 아마도 알맞지 않을 것입니다. 이 상황을 해결하기위한 한가지 방법은 다음과 같은 방식으로 점진적으로 변경하는 과정을 가지는 것입니다 :
이 전략은 기존의 데이타 모델에서 엔티티 그룹을 사용함으로써 이벤츄얼 컨시스턴시 때문에 발생하는 이슈의 리스크를 최소화할 수 있는 새 데이터 모델로 점진적 마이그레이션을 가능하게 합니다. 실제에서 이러한 접근방식은 특수한 경우들과 실제 시스템의 어플리케이션을 위한 요구사항들에 따라 달라질 수 있습니다. Degraded 모드로 뒷걸음질현재 프로그램적으로 어플리케이션이 컨시스턴시 문제 발생 상황을 알아차리는 것은 어렵습니다. 하지만 잘못된 컨시스턴시를 가진 어플리케이션이 아닌 다른 수단으로 처리하는 것을 사용할 수 있다면, 아마도 스트롱 컨시스턴시를 필요로하는 로직부분을 비활성화했다 안했다 할 수 있는 degraded mode를 구현하는 것이 가능할 것입니다. 예를 들어 결제 보고서 화면에 잘못된 쿼리 결과를 보여주는 것 대신에 유지보수 메세지를 표시하는 것이 가능합니다. 이러한 방식은 어플리케이션의 다른 서비스들은 계속해서 제공될 수 있으고 사용자 경험에 나쁜 영향을 줄여줄 수 있습니다. 완전한 컨시스턴시 확보를 위한 시간 최소화하기수백만의 사용자 또는 테라바이트의 구글 클라우드 데이터스토어 엔티티들을 가지는 대형 어플리케이션에서 구글 클라우드 데이터스토어의 잘못된 사용은 컨시스턴시 문제를 악화시킬 가능성이 있습니다. 다음과 같은 사례들이 그에 해당됩니다 :
이러한 사례들은 작은 어플리케이션들에서는 영향이 없습니다. 하지만 어플리케이션이 정말 크게 성장한 경우에는 이러한 사례들은 컨시스턴시를 위한 시간을 길게 가져갈 가능성이 증가합니다. 그래서 어플리케이션 디자인의 초기단계에서 이러한 것들을 피하는 것이 최선입니다. 피해야할 패턴 #1: 엔티티 키들의 순차적 넘버링앱엔진 SDK 1.8.1 릴리즈 이전에는 구글 클라우드 데이터스토어는 자동 생성되는 키이름에 일반적으로 연속적 패턴을 가지는 작은 정수의 ID들을 사용했습니다. 몇몇 문서에 이것은 어플리케이션에서 엔티티 생성시 키를 명시하지 않은 경우를 위한 앱엔진 SDK 1.8.1에서 구글 클라우드 데이터스토어는 분산된 ID들을 사용하는 기본값 정책을 사용하는 새 ID 넘버링 방식을 소개했습니다 (참조문서를 보세요). 이 기본값 정책은 최대 16자리를 가지는 대략 균일하게 분포된 랜덤한 순서의 ID를 생성합니다. 이 정책을 사용함으로써 대형 어플리케이션의 트래픽은 컨시스턴시를 위한 시간은 줄어들면서 구글 클라우드 데이터스토어 서버들 세트로 보다 잘 분산될 것입니다. 이 기본값 정책은 기존의 정책과의 호환성이 필요한 특정 어필리케이션이 아닌 이상 추천됩니다. 만약 엔티티에 키이름을 명시적으로 설정했다면, 명명 방식은 반드시 모든 키이름 영역전체에 골고루 엔티티들이 접근하도록 디자인 되어야합니다. 다시말해, 키이름들이 사전적으로 정렬된 것 같은 특정 범위에 접근이 집중되어서는 안됩니다. 그러지 않으면 순차적 넘버링과 동일한 이슈가 발생할 것 입니다. 키스페이스를 통한 접근의 치우침을 이해하기위해 아래의 코드에서 보이는 것 같은 순차적 키이름들로 생성된 엔티티들을 사례로 생각해봅시다: 이러한 어플리케이션 접근 패턴은 키이름들의 특정 범위를 통해 아마도 최근에 생성된 반대로 키스페이스를 통해 고른 분배을 이해하기 위해 키이름들을 긴 랜덤 문자열을 사용하는 경우를 생각해봅시다. 이건 아래의 예제와 같습니다: 이제는 최근에 생성된 피해야할 패턴 #2: 너무 많은 인덱스들구글 클라우드 데이터스토어에서 엔티티 하나의 수정은 엔티티 카인드에 정의된 모든 인덱스들을 수정하게 됩니다(자세한 것은 데이터스토어 작성의 삶을 보세요). 만약 어플리케이션이 많은 커스텀 인덱스들을 사용하고 있다면, 하나의 수정은 수십개, 수백개, 또는 수천개의 인덱스 테이블 수정을 일이킬 수 있습니다. 대형 어플리케이션에서 과도한 커스텀 인덱스의 사용은 서버 부하 증가의 원인이 될 수 있습니다. 그리고 컨시스턴시 보장을 위한 대기시간이 증가할 수 있습니다. 대부분의 경우, 커스텀 인덱스들은 고객지원, 문제 해결 또는 데이터 분석 작업과 같은 지원 요청에 의해 추가됩니다. 구글 빅쿼리는 인덱스 생성이 안된 대형 데이터셋에서 애드혹 쿼리 실행이 가능한 대용량 확장 쿼리엔진입니다. 빅쿼리는 구글 데이터 스토어보다 고객 지원,문제해결 또는 복잡한 쿼리들이 필요한 데이터 분석과 같은 경우에 더 적합합니다. 한가지 예는 다른 비즈니스 요청을 처리하기 위해 데이터 스토어와 빅쿼리를 섞어 사용하는 것입니다. 코어 어플리케이션 로직에서 필요한 온라인 트랜잭션 처리(OLTP)를 위해서는 구글 클라우드 데이터 스토어를 사용하시고, 백엔드 동작을 위한 온라인 분석 처리(OLAP)를 위해서는 구글 빅쿼리를 사용하십시요. 이런 쿼리들이 필요한 데이터들을 옮기는 것은 구글 클라우드 데이터 스토어에서 빅쿼리로 지속적인 데이터 추출 플로우를 구현해야할 것입니다. 커스텀 인덱스를 위한 대체 구현말고 다른 추천방법은 명시적으로 인덱스하지 않는 프로퍼티들을 지정하는 것입니다(Properties and value types를 보세요]). 기본적으로 구글 클라우드 데이터스토어는 엔티티 카인드의 각 인덱스 속성들을 위해 별도의 인덱스 테이블을 생성합니다. 만약 하나의 카인드에 100개의 속성들을 가지고 있다면, 그 카인드를 위한 100개의 인덱스 테이블이 존재할 것이고 매번 엔티티를 수정할때마다 백번의 추가 수정이 발생할 것입니다. 그래서 가장 잘된 예는 쿼리 조건에서 필요하지 않은 속성들은 인덱스 되지 않도록 설정하는 것입니다. 컨시스턴시를 위한 처리시간이 증가될 가능성을 줄이기는 것 뿐아니라 이 인덱스 최적화는 인덱스들을 많이 사용하는 대형 어플리케이션 안의 구글 클라우드 데이터스토어 비용 절감에 탁월한 결과를 보여줄 것입니다. 결론이벤츄얼 컨시스턴시는 확장성, 성능 그리고 컨시스턴시 사이에서 적절한 균형을 개발자가 찾을 수 있게 해주는 비관계형 데이터베이스의 기본적 요소입니다. 여러분들의 어플리케이션의 최적화된 데이터 모델을 위해 이벤츄얼 컨시스턴시와 스트롱 컨시스트 균형을 조절하는 방법을 이해하는 것은 중요한 일입니다. 구글 클라우드 데이터 스토어에서 엔티티 그룹의 사용과 엔세스터쿼리는 엔티티들간의 스트롱 컨시스턴시를 보장하기 위한 최고의 방법입니다. 만약 어플리케이션에서 앞에 설명했던 제약들로 인해 엔티티 그룹을 활용할 수 없다면, 키전용 쿼리 또는 멤캐쉬를 사용하는 것과 같은 다른 방법들을 고려할 수도 있을 것입니다. 대형 어플리케이션들을 위해 분산된 ID를 사용하는 것, 컨시스턴시 확보 시간을 줄이기위해 인덱스를 줄이는 방법과 같은 좋은 방법들을 적용하세요. 복잡한 쿼리를 위한 비즈니스 요구사항들을 수행하기위해 구글 클라우드 데이터스토어와 빅쿼리를 섞어 사용하는 것과 가능한 구글 클라우드 데이터스토어 인덱스들의 사용을 줄이는 것 또한 중요할 것입니다. 추가 자료뒤의 자료들은 이 문서에서 다뤘던 주제들에 대하여 더 많은 정보들을 제공할 것입니다. (원문은 자료가 모두 python기준으로 연결되어있었지만 제가 Java쟁이 임으로 Java자료로 링크교체 하였습니다.) Google App Engine: Storing Data Mastering the Datastore (series) Google Cloud Platform Blog Google Cloud SQL Using Java App Engine with Google Cloud SQL Bigtable: A Distributed Storage System for Structured Data App Engine 1.5.2 SDK Released Megastore: Providing Scalable, Highly Available Storage for Interactive Services [1] 엔티티 그룹은 심지어 실제 엔티티들을 저장하는 것 없이 루트 또는 부모 엔티티의 키 하나만 지정하여 만들어질 수 있습니다. 그렇기 때문에 엔티티 그룹 기능들은 모두 키들사이의 관계를 기반으로 구현되어 있습니다. [2] 지원되는 제약은 트랜잭션 밖에서 엔티티 그룹당 1초에 하번의 수정 또는 엔티티 그룹당 1초에 하나의 트랜잭션 입니다. 만약 하나의 트랜잭션에서 복수의 수정을 처리해야한다면, 10MB의 최대 트랜잭션 사이즈와 데이터 스토어의 최대 작성율이 제한될 것입니다. |
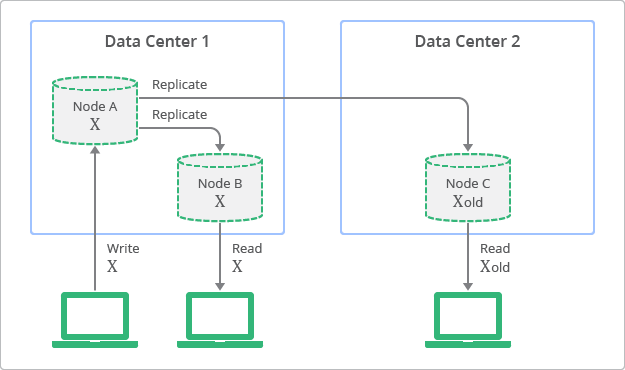
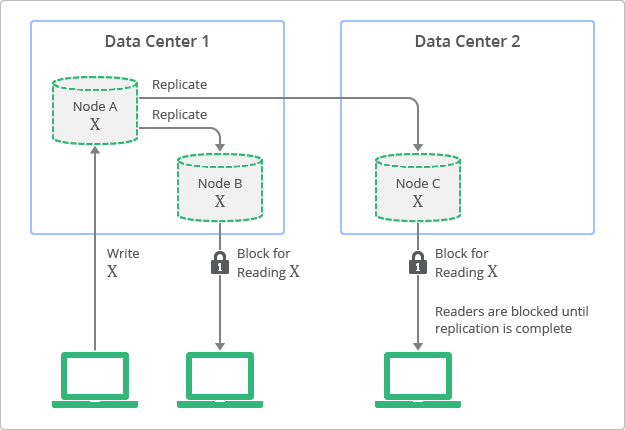
 그림 3: 엔티티 그룹 컨셉
그림 3: 엔티티 그룹 컨셉